
近日,中国科学院自动化研究所李国齐与徐波领衔的科研团队正式推出全球首个大规模类脑脉冲大模型——spikingbrain1.0。该模型在处理超长文本方面表现卓越,能够以超过现有主流 transformer 模型百余倍的速度完成400万 token 的文本处理任务,同时仅需其2%的训练数据量。
目前广泛应用的大语言模型,如GPT系列,大多依赖于Transformer架构。尽管其自注意力机制具备强大的语义捕捉能力,但随之而来的高计算复杂度成为显著瓶颈。当输入文本长度增加时...
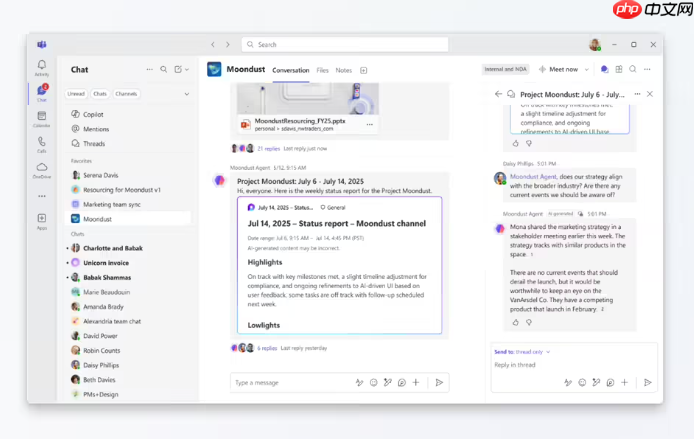
微软已正式发布全新AI助手“Channel Agent”,该功能现已以公共预览形式登陆 Microsoft Teams 的 Windows、Mac、iOS、安卓及网页版本。Channel Agent 的目标是增强团队协作的智能化水平,协助用户更高效地管理项目进程与日常任务。
每个新建的频道将自动配备一位与频道同名的智能助手。这位助手具备生成结构化 Loop 报告的能力,并能结合会议记录和 Planner 任务信息,精准回应团队成员提出的问题。通过 Channel A...
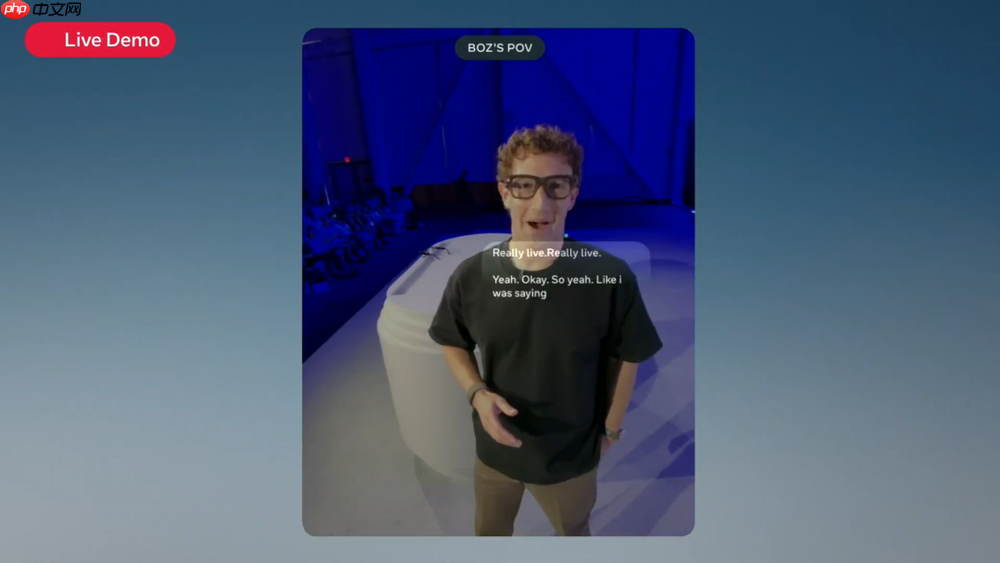
在近日举行的Meta Connect 2025大会上,Meta CEO马克·扎克伯格于美国加州舞台亲自为公司新款定价约800美元的Ray-Ban智能眼镜进行现场演示,却遭遇多次技术故障,场面一度尴尬。面对接连出错的AI指令和连接问题,他最终将问题归因于“网络太差”,引发全场哄堂大笑。
活动中,扎克伯格连线厨师杰克·曼库索,试图通过眼镜内置AI助手实时指导制作韩式风味牛排酱。然而AI系统错误判断步骤,跳过关键环节;即便重启尝试,问题依旧重现。对此,他苦笑回应:“讽刺的...

近日,阿里云重磅宣布通义万相全新动作生成模型 wan2.2-animate 正式开源,此举有望为短视频创作、舞蹈模板生成以及动漫制作等行业注入全新动力。开发者和创作者可通过 github、huggingface 及魔搭社区免费获取该模型及其完整代码。同时,用户还能通过阿里云百炼平台调用其 api,或直接访问通义万相官网在线体验模型的强大能力。
Wan2.2-Animate 是在前代模型 Animate Anyone 的基础上实现全面进化的成果,在人物一致性、画面清晰...

2025年9月19日,阿里云正式宣布通义万相推出全新动作生成模型——wan2.2-animate,并全面开源。该模型可驱动人物、动漫形象及动物图片实现动态化,广泛适用于短视频创作、舞蹈模板生成、动画制作等场景。开发者和创作者可通过 github、huggingface 以及魔搭社区免费下载模型权重与代码,也可通过阿里云百炼平台调用 api,或直接在通义万相官网进行在线体验。
作为此前开源项目 Animate Anyone 的全面升级版本,Wan2.2-Animate 在...

在近期科技领域的新进展中,xai 公司正式发布了其轻量级旗舰模型 grok4fast。这一新型模型不仅在性能层面实现显著跃升,更在运行成本方面带来颠覆性优化,展现出强劲的市场竞争力。
Grok4Fast 的最大优势在于计算需求减少了40%,使其在应对高复杂度任务时响应更快、效率更高,尤其适合对实时性要求严苛的应用场景。更引人注目的是,单次任务的运行成本降幅高达98%。对企业而言,这意味着在维持高性能输出的同时,可大幅削减运营支出,极具吸引力。
该模型具备高达200...
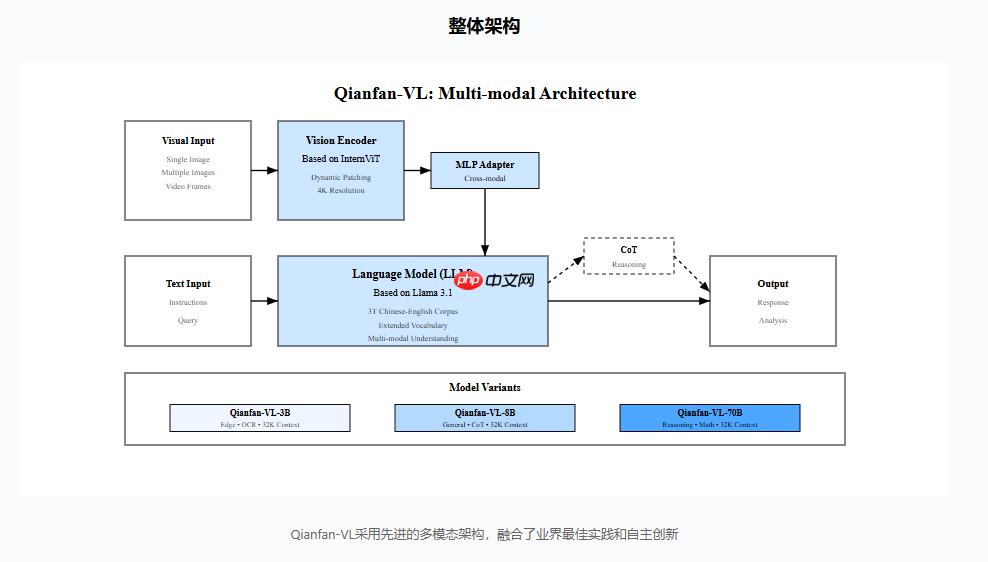
百度智能云千帆团队近日正式推出了全新视觉理解模型 Qianfan-VL,并宣布全面开源!该系列涵盖3B、8B 和70B 三种不同参数规模的版本,专为满足企业级多模态应用需求而设计。经过深度优化,模型在视觉理解方面展现出卓越的能力。
Qianfan-VL 不仅具备强大的基础性能,还针对行业高频应用场景进行了重点增强,特别是在光学字符识别(OCR)和教育领域表现突出,显著提升了实际使用中的效果。该模型基于开源架构研发,并在百度自研的昆仑芯 P800 平台上完成全链路...

在刚刚落幕的华为全联接大会上,华为技术有限公司携手浙江大学共同发布了国内首款基于昇腾千卡算力平台打造的基础大模型——DeepSeek-R1-Safe。该模型聚焦当前人工智能领域中的安全与性能难题,标志着我国在AI安全技术研发方面迈出了关键一步。

浙江大学计算机科学与技术学院院长任奎现场深入解读了该模型的技术亮点。他表示,DeepSeek-R1-Safe 采用了一套完整的安全后训练框架,涵盖高质量安...
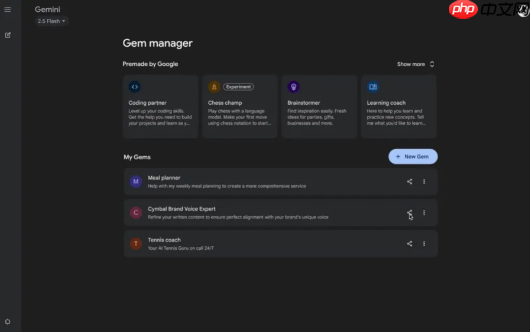
谷歌在本周四宣布,其个性化AI助手Gemini Gems现已支持共享功能。这项能力最初作为付费订阅服务的一项权益推出,允许用户构建专为特定用途定制的AI聊天机器人,例如学习辅导、文案润色或编程协助。
现在,用户可以像分享Google Drive中的文件一样,便捷地将自己创建的Gems发送给朋友、家人或团队成员。谷歌表示,此举意在提升这些定制化AI工具的可访问性,并减少重复开发相似助手的情况。举例来说,若一个项目团队中的多名成员都需要类似的Gem,他们可以直接共用同一...

在当前人工智能的前沿探索中,yann lecun 提出的 jepa(联合嵌入预测架构)正逐步重塑大语言模型(llm)的训练范式。这位图灵奖得主并未止步于对现有 llm 的批评,而是亲自投身于模型架构的革新。传统 llm 的训练依赖输入空间中的序列生成任务,例如逐词预测,这种机制虽然广泛应用,但在表征学习方面已显露出瓶颈,尤其在类比视觉领域的任务中暴露出效率与泛化能力的不足。
LeCun 与其研究团队提出,应从计算机视觉(CV)的成功经验中汲取灵感,以推动语言模型的进...